── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(ggformula)
Loading required package: scales
Attaching package: 'scales'
The following object is masked from 'package:purrr':
discard
The following object is masked from 'package:readr':
col_factor
Loading required package: ggridges
New to ggformula? Try the tutorials:
learnr::run_tutorial("introduction", package = "ggformula")
learnr::run_tutorial("refining", package = "ggformula")
library(babynames)
babynames
# A tibble: 1,924,665 × 5
year sex name n prop
<dbl> <chr> <chr> <int> <dbl>
1 1880 F Mary 7065 0.0724
2 1880 F Anna 2604 0.0267
3 1880 F Emma 2003 0.0205
4 1880 F Elizabeth 1939 0.0199
5 1880 F Minnie 1746 0.0179
6 1880 F Margaret 1578 0.0162
7 1880 F Ida 1472 0.0151
8 1880 F Alice 1414 0.0145
9 1880 F Bertha 1320 0.0135
10 1880 F Sarah 1288 0.0132
# ℹ 1,924,655 more rows
The table displays baby names from 1880-2017, showing how frequently each name was given and its proportion among all births that year.
Looking up the name “Aditi”
babynames %>%filter(name=="Aditi")
# A tibble: 40 × 5
year sex name n prop
<dbl> <chr> <chr> <int> <dbl>
1 1977 F Aditi 5 0.00000304
2 1978 F Aditi 9 0.00000548
3 1979 F Aditi 9 0.00000522
4 1980 F Aditi 6 0.00000337
5 1982 F Aditi 10 0.00000551
6 1983 F Aditi 12 0.00000671
7 1984 F Aditi 10 0.00000555
8 1985 F Aditi 17 0.00000921
9 1986 F Aditi 22 0.0000119
10 1987 F Aditi 21 0.0000112
# ℹ 30 more rows
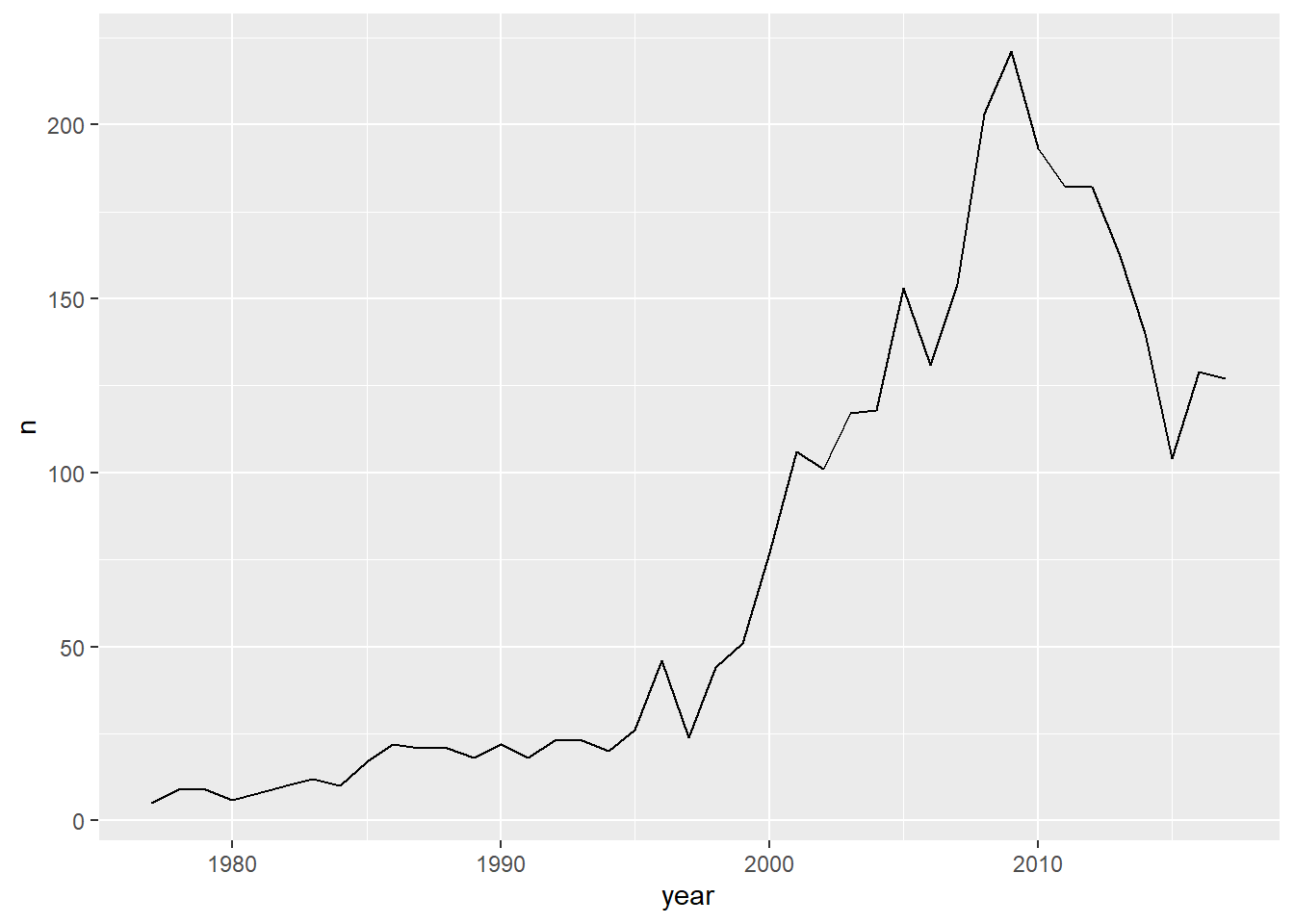
This table displays the usage of the name “Aditi” for baby girls in the United States between 1977 and 2017. The name was initially quite uncommon, with fewer than 10 occurrences annually from 1977 to 1982. Over the years, however, it steadily gained popularity. The peak was in 2008, when 203 baby girls were named Aditi, accounting for 0.0009755 of all female births that year. After 2008, the name’s popularity varied slightly but remained fairly stable, with a gradual decline in the following years. By 2017, 127 baby girls were named Aditi, representing 0.0006774 of female births.
The line graph shows the trend in the popularity of the name “Aditi” for baby girls in the United States from 1977 to 2017. The y-axis (n) represents the number of babies given the name each year, while the x-axis (year) tracks the years over time.The graph clearly illustrates a significant rise followed by a gradual decline.
Looking up my name -“Khushi” and another possible spelling -“Kushi”
# A tibble: 30 × 5
year sex name n prop
<dbl> <chr> <chr> <int> <dbl>
1 1999 F Khushi 5 0.00000257
2 2000 F Khushi 6 0.00000301
3 2001 F Khushi 44 0.0000222
4 2002 F Khushi 89 0.0000451
5 2003 F Khushi 178 0.0000888
6 2003 F Kushi 9 0.00000449
7 2004 F Khushi 132 0.0000655
8 2005 F Khushi 86 0.0000424
9 2005 F Kushi 9 0.00000444
10 2006 F Khushi 69 0.0000330
# ℹ 20 more rows
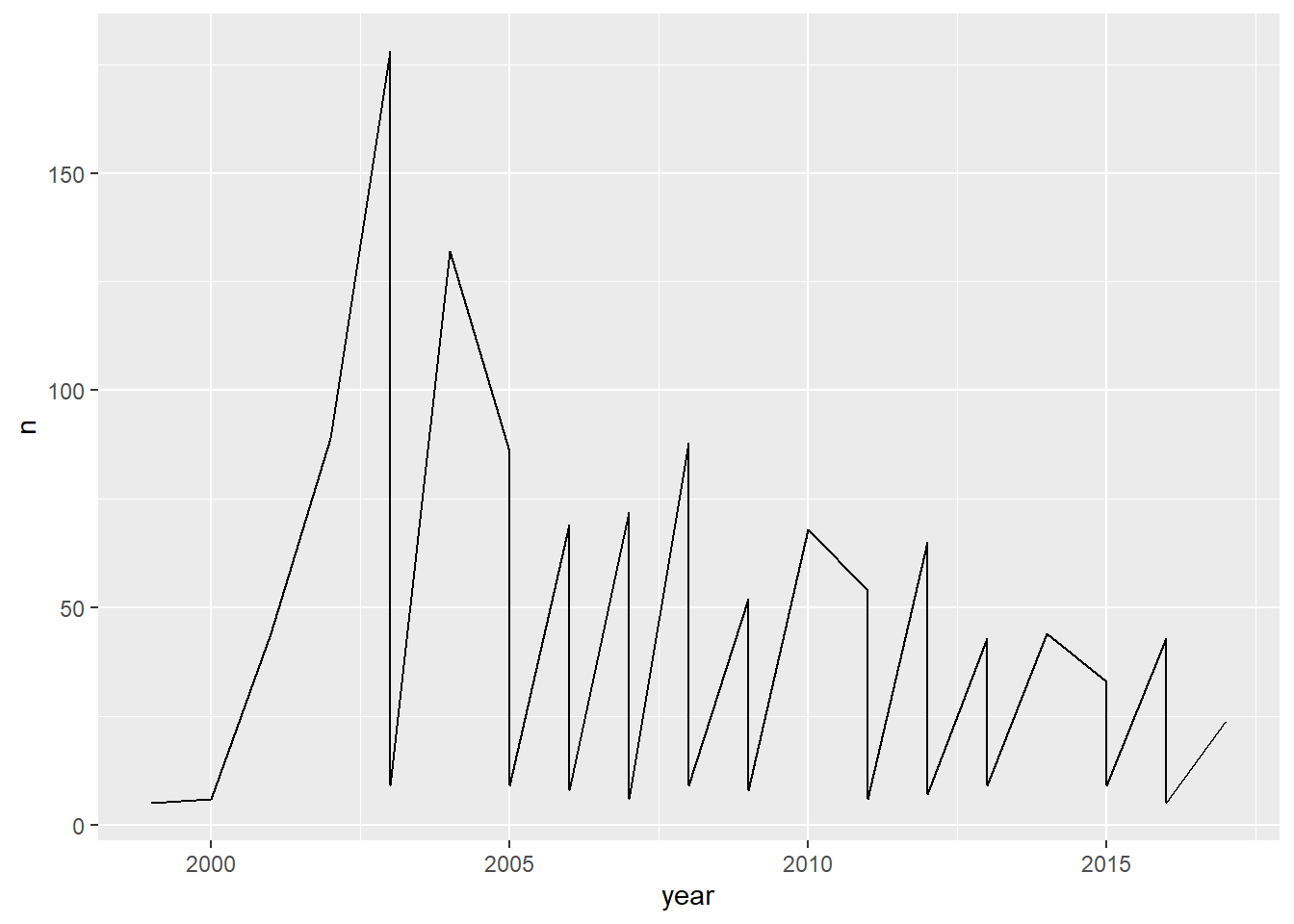
The comparison between the spellings “Khushi” and “Kushi” reveals notable trends. Neither name appeared in the U.S. dataset from 1880 to 1999, and both first emerged in 1999 with very low occurrences. However, “Khushi” quickly became more popular, while “Kushi” remained relatively rare. By 2003, 178 baby girls were named “Khushi,” compared to just 9 named “Kushi,” and this pattern persisted in the following years. Overall, “Khushi” consistently saw higher usage, demonstrating how different spellings of the same name can experience varying levels of adoption over time.
Plotting a Line graph for my name -“Khushi” and another possible spelling -“Kushi”
This line graph illustrates the trend in the popularity of the names “Khushi” and “Kushi” for baby girls in the U.S. from 1999 to 2017. The y-axis (n) represents the number of babies named each year, and the x-axis (year) tracks the timeline.
Looking up my roommate’s name -“Anousha”
babynames %>%filter(name=="Anousha")
# A tibble: 3 × 5
year sex name n prop
<dbl> <chr> <chr> <int> <dbl>
1 2006 F Anousha 6 0.00000287
2 2007 F Anousha 9 0.00000426
3 2013 F Anousha 5 0.0000026
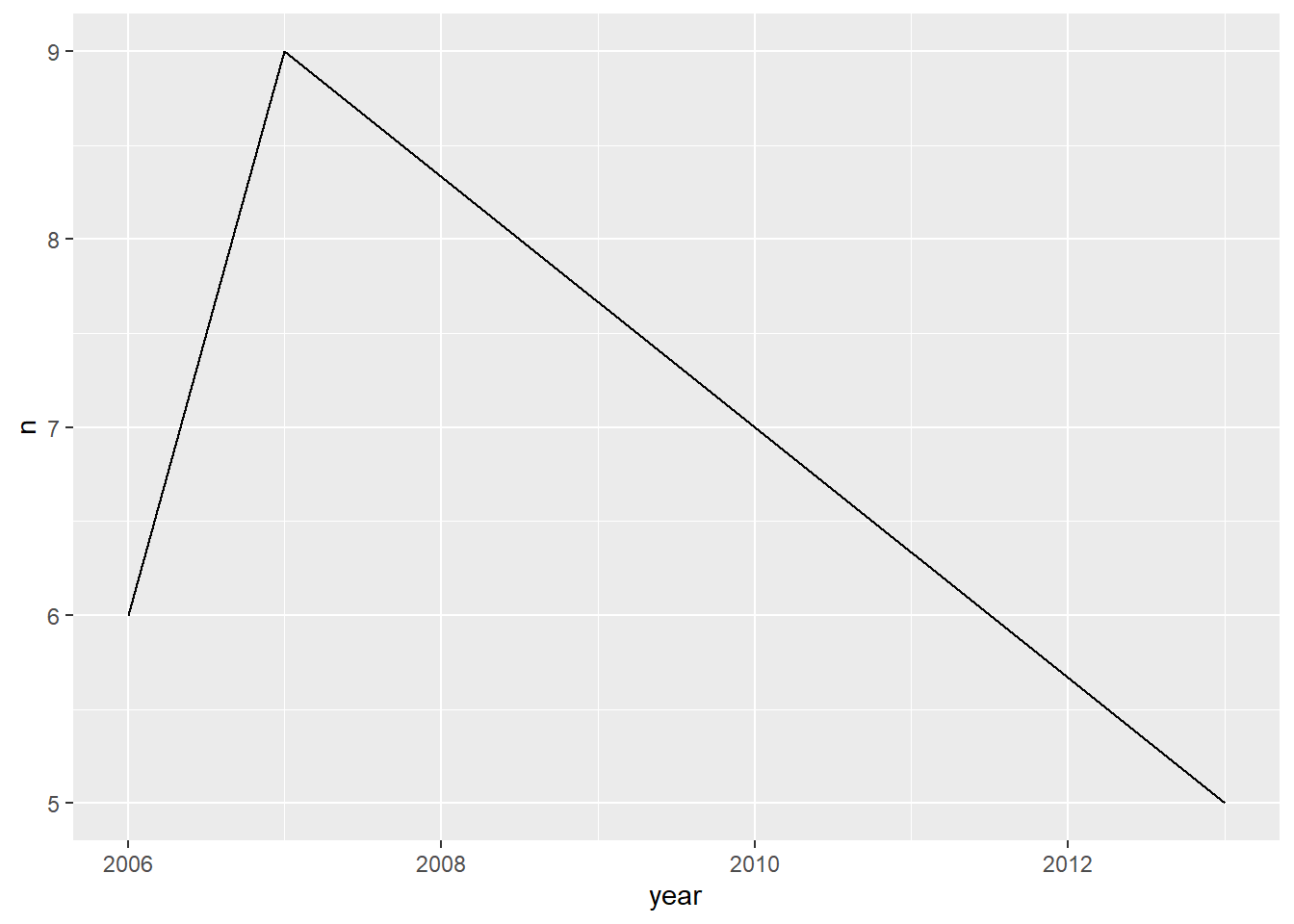
The name “Anousha” is extremely rare in the “babynames” dataset, which spans from 1880 to 2017. Despite the large timeframe, the name appears only three times: in 2006, 2007, and 2013. In each of these years, the number of baby girls named Anousha was very low, with a maximum of just 9 occurrences in 2007.
Plotting a Line graph for my roommate’s name -“Anousha”
This line graph shows the trend in the number of baby girls named “Anousha” in the U.S. from 2006 to 2013. The y-axis (n) represents the number of occurrences each year, while the x-axis (year) tracks the time period.